
최근 대형언어모델(LLM)을 사내 인프라나 개인 개발 환경에 자체적으로 구축하는 로컬 LLM 도입 흐름이 가속화되고 있습니다. 클라우드 기반의 상용 API 서비스는 편리하게 사용할 수 있다는 장점이 있지만, 데이터 유출에 대한 우려, 지속적인 호출 비용 상승, 그리고 인터넷 연결이 단절된 환경에서의 제한적 사용 등 명확한 한계를 지니고 있습니다. 특히 소스 코드, 기업 기밀, 개인정보 등 외부 유출이 법적으로 엄격히 금지된 데이터를 다루는 작업의 경우, 네트워크 외부 전송을 원천 차단한 독립적인 로컬 LLM 환경의 확보는 필수적입니다.
이러한 로컬 인프라를 성공적으로 가동하기 위해서는 단순한 일회성 실행을 넘어, 외부 클라이언트나 타 개발 도구들이 표준 규격으로 소통할 수 있는 안정적인 API 서버 환경을 조성해야 합니다. 본 가이드에서는 고성능 로컬 AI 서버의 하드웨어로 각광받는 Mac Studio 환경을 주축으로 삼아, 경량 추론 엔진인 Ollama의 시스템 백그라운드 자동 구동 체계를 확립합니다. 나아가 외부 원격 접속 시의 보안 유출을 방지하기 위한 Nginx 리버스 프록시 연동 및 사용자 인증 도입 수칙, 그리고 실제 애플리케이션 코딩에 접목하기 위한 파이썬 연동 엔지니어링까지 엔드투엔드로 상세히 기술합니다.
01. 온프레미스 AI 인프라의 가치와 서버 구축의 필요성
로컬 LLM의 필요성은 단순한 비용 문제를 넘어 보안과 직결됩니다. 많은 개발 팀이 코딩 어시스턴트나 데이터 검색 시스템을 구축할 때 클라우드 API를 쓰지만, 이는 내부 소스 코드나 고객 데이터가 외부 서버로 나가는 리스크를 안고 있습니다. 물리적으로 네트워크가 차단되거나 basic_auth 등으로 격리된 망 내에 전용 로컬 서버를 두는 아키텍처는 기밀 유출을 사전에 완벽히 차단해주는 가장 유용한 안전장치입니다.
02. 하드웨어 최적화 비교 분석: Mac Studio vs 엔비디아 그래픽 카드 및 가속기
로컬 LLM 서버를 구축할 때 가장 먼저 맞닥뜨리는 의문은 바로 어떤 연산 하드웨어를 선택하느냐입니다. 전통적인 기계학습 워크플로우에서는 엔비디아의 CUDA 생태계가 표준으로 군림해 왔으나, 최근 애플 실리콘(Apple Silicon)의 통합 메모리 아키텍처(UMA)가 거대 모델 추론 영역에서 압도적인 가성비와 자원 효율을 보여주며 핵심 대안으로 급부상했습니다. 각 하드웨어의 아키텍처 특징과 실증 성능 지표를 정밀 대조합니다.
대형언어모델의 추론(Inference) 단계는 연산 장치의 연산 속도(FLOPS)보다 데이터를 메모리로부터 실어 나르는 메모리 대역폭(Memory Bandwidth)에 의해 최종 성능이 결정되는 메모리 바운드(Memory-bound) 특성을 지닙니다. 생성 토큰 하나를 연산할 때마다 모델 전체 가중치(Weights) 텐서를 매번 메모리 칩에서 가져와 연산 유닛에 공급해야 하기 때문입니다.
| 하드웨어 사양 | 메모리 대역폭 | Llama3 8B (Q4) | Llama3 70B (Q4) | 아이들 전력 |
|---|---|---|---|---|
| Nvidia RTX 4090 (24GB) | 1,008 GB/s | 112 t/s | OOM (구동 불가) | 220W |
| Mac Studio M4 Max (64GB) | 546 GB/s | 92 t/s | 14 t/s | 12W |
| Mac Studio M3 Ultra (128GB) | 819 GB/s | 118 t/s | 21 t/s | 15W |
| Nvidia A100 (80GB) | 1,935 GB/s | 135 t/s | 22 t/s | 120W |
실증 데이터 분석 결과를 보면, 속도 자체는 초당 전송량이 높은 엔비디아 시스템이 앞서지만 70B 모델 이상의 영역에서는 단일 GPU 한계로 인해 Mac Studio의 메모리 용량 우위가 두드러집니다. 특히 전력 효율성의 차이는 극적입니다. 24시간 중단 없이 켜두어야 하는 API 서버 특성상, 아이들링 상태에서 200W 이상을 계속 낭비하는 RTX 4090 시스템에 비해 Mac Studio는 대기 시 전력 소모량이 15W 미만으로 일반 스마트폰 충전기 수준에 불과합니다. 이는 장기 인프라 운영 비용을 획기적으로 낮춰 주는 실질적인 경제적 가치를 증명합니다.
03. 최신 로컬 AI 구동 플랫폼 비교 및 분석
로컬 환경에서 인공지능 모델을 실행해 주는 소프트웨어 프레임워크와 런타임 인터페이스는 여러 종류가 존재합니다. 각 플랫폼은 타깃으로 삼는 사용자와 개발 성향에 따라 각기 다른 장단점을 지니고 있습니다. 다음은 최신 로컬 AI 구동 플랫폼 5종의 아키텍처 지원 사양과 정량적 특징을 대조한 Matrix 지표입니다.
| 플랫폼 명칭 | 지원 포맷 | 주요 API 및 GUI | 자원 오버헤드 | 최적 권장 영역 |
|---|---|---|---|---|
| Ollama | GGUF | OpenAI API 호환 / GUI 미지원 (CLI 전용) | 매우 낮음 (100MB 미만) | 개발망 통합 및 멀티 에이전트 연동 |
| LM Studio | GGUF | OpenAI API 호환 / GUI 탑재 (수려함) | 보통 (300MB ~ 500MB) | 초심자 입문 및 단일 모델 신속 테스트 |
| Jan | GGUF, TRT-LLM | OpenAI API 호환 / GUI 탑재 (ChatGPT 클론) | 보통 (200MB ~ 400MB) | 개인 데이터 보호 중심 프라이버시 챗봇 |
| KoboldCPP | GGUF, GGML | Kobold API 호환 / GUI 탑재 (레트로 웹 UI) | 낮음 (데몬 가벼움) | 장기 기억 제어 기반 소설/역할극 게임 |
| Text Gen WebUI | EXL2, GPTQ, AWQ, GGUF | OpenAI API / Web UI 탑재 (Gradio 웹 UI) | 높음 (파이썬 스택 무거움) | LORA 미세조정 및 연구용 파라미터 튜닝 |
각 플랫폼별 세부 아키텍처 특징과 실무 운용 관점에서의 장단점 해설 요약본입니다.
Ollama
가볍고 빠른 백그라운드 구동 데몬. OpenAI 규격 API 자동 노출 지원으로 개발 연동성에 특화되었으나, CLI 중심 동작으로 GUI 환경이 제공되지 않습니다.
LM Studio
Hugging Face 모델 다이렉트 검색 및 원클릭 다운로드와 같은 미려하고 편리한 GUI를 선사하지만, 비공개 소스 라이선스이며 GUI 오버헤드가 다소 있습니다.
Jan
ChatGPT 클론 형태의 수려한 완전 오픈소스 챗 UI. 철저한 데이터 프라이버시 오프라인 가동에 특화되었으나 다중 스레드 병렬 처리가 약간 무겁습니다.
KoboldCPP
역할극 및 텍스트 모험 게임용 스토리 장기 기억 제어에 탁월하며 GGUF 호환성이 광범위하지만, GUI 디자인이 투박하고 일반 비즈니스용에 부적합합니다.
Text Generation WebUI
모델 미세조정(Fine-tuning), LoRA 학습 및 매개변수 미세 튜닝을 모두 포괄하는 강력한 도구이나 파이썬 패키지 충돌이 잦아 관리가 까다롭습니다.
3.1. Ollama (경량화와 개발 연동성의 최강자)
Ollama는 가볍고 빠른 백그라운드 서비스(데몬) 형태로 동작하여 시스템 자원 점유율이 극히 낮습니다. 터미널 환경에서 단순한 명령어로 신속히 모델을 교체할 수 있고, 자체적인 OpenAI 호환 API 서버를 백그라운드에 자동으로 기동하므로 타 어플리케이션과의 내부 연동성이 극도로 우수합니다. 특히 API 서버 구축 시 불필요한 일렉트론(Electron) GUI 오버헤드가 전혀 없어 메모리를 1MB라도 더 확보해야 하는 로컬 인프라 환경에서 최고의 안정성을 제공합니다. 다만 단점으로는 자체적으로 탑재된 그래픽 사용자 인터페이스(GUI)가 완전히 부재하여 CLI 환경에 익숙하지 않은 일반 사용자에게는 초기 진입 장벽이 높습니다.
3.2. LM Studio (플러그 앤 플레이의 정수)
LM Studio는 현존하는 가장 완성도 높고 미려한 로컬 GUI를 지원합니다. 허깅페이스(Hugging Face) 저장소와 직통 연결되어 사용자가 원하는 양자화 모델을 즉석에서 검색하고 단 한 번의 클릭으로 다운로드하여 테스트할 수 있는 혁신적인 편의성을 자랑합니다. 그러나 단점으로는 소스 코드가 공개되지 않은 비개방형(Closed Source) 상용 라이선스를 사용하고 있어 기업 내부망 보안 심사 통과에 제약이 있을 수 있으며, 백그라운드 구동에 비해 GUI 엔진이 상시 실행되므로 메모리 오버헤드가 더 큽니다.
3.3. Jan (오픈소스 ChatGPT 지향 프라이버시 챗봇)
Jan은 일렉트론 기반의 깔끔하고 현대적인 오픈소스 챗 클라이언트입니다. 완전한 오프라인 작동 및 데이터 프라이버시 보호에 초점을 맞추고 있으며, 깔끔하게 정돈된 설정창을 통해 OpenAI API 키 연동과 로컬 추론을 자유롭게 전환할 수 있습니다. 단점으로는 백그라운드 서빙 전용으로 특화되지 않아 대규모 다중 접속 및 라우팅 관리가 다소 제한적이며, 일렉트론 프레임워크 자체의 고질적인 메모리 소모 현상이 수반됩니다.
3.4. KoboldCPP (스토리 작문과 역할극의 숨은 강자)
KoboldCPP는 웹 소설 창작, 역할극(Roleplay) 및 텍스트 어드벤처 게임 매니아들을 위해 극도로 특화된 파라미터 설정을 지원합니다. 다양한 GGUF 파생 포맷의 호환성이 뛰어나며, 장기 기억(Context Window) 제어와 프레이즈 밴(Banned words) 처리가 정교하여 긴 텍스트 생성의 흐름이 끊기지 않는 장점이 있습니다. 그러나 디자인 인터페이스가 직관적이지 못하고 복잡하여 일반적인 업무 보조용 Q&A나 범용 API 서버 목적으로 쓰기에는 가독성이 현저히 떨어진다는 명확한 한계를 지닙니다.
3.5. Text Generation WebUI (파워 유저 및 연구용 스위스 아미 나이프)
Text Generation WebUI(Oobabooga)는 로컬 AI계의 웹 UI 끝판왕으로 불리며, 미세조정(Fine-tuning), LoRA 훈련, 다중 모델 병렬 적재, 다양한 양자화 백엔드(ExLlama, GPTQ, AWQ)를 자유롭게 넘나들 수 있습니다. 특히 GPU VRAM을 효율적으로 분할하는 레이어 분산 제어 기능이 극대화되어 있습니다. 다만 단점으로는 설치 패키지의 크기가 매우 방대하며 파이썬 라이브러리 간의 버전 충돌이 빈번하게 발생하여 유지관리 및 설치 난이도가 극도로 높고 구동 환경이 상대적으로 불안정합니다.
04. 최신 오픈소스 로컬 LLM 모델 엔진 및 MoE 아키텍처 분석
로컬 AI 인프라를 성공적으로 가동하기 위해서는 구동 플랫폼뿐만 아니라, 그 플랫폼 위에서 구동할 핵심 AI 엔진인 오픈 가중치(Open-Weight) 거대언어모델(LLM)의 특성을 정확히 파악해야 합니다. 최신 트렌드를 이끄는 대표 엔진들과 고효율 MoE 아키텍처의 실무적 장단점을 대조 분석합니다.
4.1. 주요 로컬 LLM 엔진 모델 라인업 및 특징
로컬 개발 및 운영 환경에서 가장 널리 검증되고 활용되는 대표적인 LLM 엔진 5종의 아키텍처와 활용 전략은 다음과 같습니다.
DeepSeek-R1 (추론 특화)
CoT 추론을 통한 복잡 논리 및 코딩 완성에 강한 최신 엔진. 671B MoE 풀버전의 구동 병목을 해결하기 위해 Qwen/Llama 기반의 Distilled 라인업(8B~70B)이 로컬에서 적극 추천됩니다. 생각 과정이 선행되어 반응 속도(TTFT)가 지연되는 단점이 있습니다.
Qwen 2.5 & Coder (다국어/코딩)
동양권 언어(한국어) 맥락 이해와 코드 제작 속도가 아주 빠릅니다. 최신 32B Coder는 사내 개발 툴 연동 시 최상의 정확도를 입증했으며, 레거시(Qwen 2) 대비 컨텍스트 유지력이 탁월하나 서구식 복잡 법률 텍스트에서는 미세한 약세가 존재합니다.
Llama 3.1 & 3.3 (산업 표준)
메타의 최신 70B 모델은 펑션 콜링 정밀도가 최상위이며, 8B 모델은 저사양 RAG 서버용으로 안착했습니다. 광범위한 라이브러리 연동 안정성이 가장 뛰어나지만 시스템 지시문이 부재하면 번역투 문장을 기입하는 단점이 수반됩니다.
Gemma 2 (구글 플래그십)
구글의 9B/27B 라인업으로 RLHF 최적화가 정교하여 인간답고 부드러운 서사적 어조를 형성합니다. 레거시 대비 환각이 크게 제어되었으나 어텐션 구조의 특이성 때문에 GGUF 전환 시 VRAM 누수 위험이 있어 데몬 컴파일 플래그 점검이 요망됩니다.
Phi-4 (MS 초소형 모델)
MS가 정제된 교과서 데이터로 훈련한 14B 초소형 모델. 작은 크기 대비 수학적 논리 연산이 매우 강력하여 가용 VRAM 8GB 미만 엣지 기기에서 고속 동작하나, 일반 상식 RAG나 문예 창작 등 비정형 텍스트에선 쉽게 문맥 누수가 발생합니다.
DeepSeek-R1 매개변수별 프로필 상세 분석
- 1.5B (Distill-Qwen) 모바일 및 초경량 IoT 기기용 테스트 모델. GGUF Q4 기준 약 1~2GB의 VRAM만 점유하여 일반 데스크톱 웹 브라우저 백그라운드에서도 작동할 정도로 가벼우나, 다단계 추론이나 고지능 코딩에서는 깊이 있는 사고 과정(thinking)이 쉽게 붕괴됩니다.
- 7B / 8B (Distill-Qwen/Llama) 비디오 메모리 8GB 이하 보급형 GPU 단말 타깃. Q4 양자화 기준 약 6~8GB의 VRAM을 점유하며, 가볍고 빠른 반응성으로 로컬 코딩 툴(IDE)의 실시간 코드 어시스턴트로 연동하기에 가성비가 가장 우수합니다.
- 14B (Distill-Qwen) 가용 VRAM 16GB(RTX 4080 등) 시스템 최적화 모델. Q4 기준 약 10~12GB VRAM을 점유하며, 7B 대비 환각 현상이 현격하게 억제되어 모듈형 함수 디자인 및 논리 연산에 강점을 보입니다.
- 32B (Distill-Qwen) 단일 GPU RTX 4090(24GB) 인프라 최강의 추론 엔진. GGUF Q4_K_M 기준 약 20~22GB VRAM을 점유하며, 70B 모델 지능에 육박하면서도 20 t/s 이상의 쾌적한 속도를 보장해 복잡한 알고리즘 리팩토링 및 데이터 엔지니어링에 활용됩니다.
- 70B (Distill-Llama) 다중 GPU 구축망 혹은 Mac Studio M4 Max 64GB급 이상 기기 최적화. Q4 기준 약 45~50GB VRAM을 요구하며, 초고부하 수학/과학 분석 및 에이전트 다단계 명령 추종에 압도적인 완성도를 보장하여 RAG 서버의 코어로 활용됩니다.
- 671B (Full MoE) 엔터프라이즈 온프레미스 인프라를 위한 궁극의 추론 모델. Q4 상태에서도 380GB~420GB 이상의 VRAM 풀이 요구되어 8-way 가속기 클러스터가 필수적입니다. API 연동 시 CoT 태그인 <think> 영역의 정규표현식(re.sub(r'<think>.*?</think>’, ”, response_text, flags=re.DOTALL)) 필터링 처리가 실무적 필수 규칙입니다.
Qwen 2.5 및 Coder 매개변수별 프로필 상세 분석
- 1.5B (범용/Coder) 모바일 엣지 디바이스나 초경량 웹 브라우저 테스트에 적합합니다. GGUF Q4 양자화 적용 시 실점유 VRAM은 약 1.2GB에서 1.5GB 선에 그쳐 온보드 메모리가 빈약한 환경에서도 원활하게 로드됩니다. 특히 Coder 1.5B 버전은 IDE 환경 내 한 줄 코드 자동 완성(Inline Completion)용 어시스턴트로 기동하기에 최상이며 10ms 이하의 쾌적한 반응 속도를 자랑합니다. 그러나 복잡한 클래스 구조 파악이나 다중 의존성 리팩토링과 같은 고부하 태스크에서는 문맥 유지력이 현저히 상실됩니다.
- 7B (범용/Coder) 8GB VRAM 그래픽 카드를 탑재한 엔트리급 개발용 워크스테이션의 표준 기점입니다. Q4 양자화 기준 실점유 VRAM은 약 5.5GB에서 6.5GB이며, 한국어의 부드러운 자연어 대화 작성을 무리 없이 수행합니다. 로컬 IDE 대화 창에서 단일 모듈 함수 설계나 세부 문법 오류 검증용으로 가장 쾌적하게 활용할 수 있는 합리적인 엔진입니다.
- 14B (범용) 가용 VRAM 16GB 장비(RTX 4080 등)에 안성맞춤인 고효율 모델입니다. 실질 VRAM 점유는 Q4 기준 약 10GB에서 12GB 내외로 측정됩니다. 7B 모델에 비해 RAG 시스템 구축 시 문서 내용 매핑 능력이 눈에 띄게 정확하며, 소스 코드 생성 시 문법적 환각 현상이 크게 감소하는 경향을 보여줍니다.
- 32B (범용/Coder) 단일 GPU RTX 4090(24GB) 및 Mac Studio 환경을 구축한 엔지니어에게 코딩 및 복잡 추론용 최종 코어로 추천하는 최고 완성도의 모델입니다. GGUF Q4_K_M 양자화 적용 시 약 20GB에서 22GB 수준의 VRAM을 점유하여 단일 4090 카드의 가용 한계를 아슬아슬하게 채웁니다. 소스 코드 리팩토링, 버그 추적, 데이터 분석 스크립트 작성에서 상용 GPT-4o 급의 완성도를 보여주며, FauxPilot이나 Cursor 등의 개발망 커스텀 엔드포인트에 연동하여 자율 개발 환경을 구성하기 위한 궁극의 대안입니다.
- 72B (범용) Mac Studio 64GB 이상 혹은 다중 GPU 클러스터가 갖춰진 온프레미스 인프라를 타깃으로 삼는 초거대 범용 모델입니다. 실질 VRAM 점유는 Q4 기준 약 45GB에서 48GB 수준입니다. 자연어 표현 능력이 가장 수려하여 사내 규정 번역, 복잡 법률 및 기술 문서 대조 RAG 시스템의 종합 판단 허브 역할을 매끄럽게 수행하며, 다단계 에이전트 시스템에 탑재되었을 때 프롬프트 붕괴 없이 시스템 지시어를 정밀하게 이행합니다.
Llama 3.1 및 3.3 매개변수별 프로필 상세 분석
- 8B (Llama 3.1) 저성능 RAG 시스템의 질문 분류, 데이터 전처리, 경량 개체명 인식(NER) 작업에 최적화된 업계 레퍼런스 모델입니다. Q4 양자화 상태에서 약 5.8GB에서 6.2GB VRAM을 소모하며(Q8 정밀도 구동 시 약 9GB 점유), 로컬 런타임 최적화와 호환성이 최상이라 구동 안정성이 매우 높습니다. 다만 한국어 자연어 성능이 다소 번역투로 딱딱하게 출력되므로, 시스템 프롬프트 단에서 명확한 출력 스타일 예시(Few-shot)를 주입하는 것이 효과적입니다.
- 70B (Llama 3.1/3.3) Mac Studio M4 Max 64GB 혹은 RTX 4090 2-way 그래픽 서버 환경의 종합 브레인 엔진입니다. GGUF Q4_K_M 기준 실점유 VRAM은 약 43GB에서 46GB를 기록합니다. 특히 최신 Llama 3.3 70B는 극도로 정교해진 펑션 콜링(Function Calling) 능력과 다중 도구 제어 신뢰성을 선사하여, 사용자의 자연어 발화를 기계가 해석 가능한 JSON 구조나 API 호출 구문으로 오차 없이 변환해 주는 로컬 엔터프라이즈 AI 에이전트 구축의 실무적 핵심 엔진입니다.
- 405B (Llama 3.1) 단일 일반 서버에서는 구동이 절대 불가능하며, A100/H100 8-way 노드 다중 연결 혹은 Mac Studio M3 Ultra 128GB 장비 다수를 분산 프레임워크로 엮어야 가동할 수 있는 초거대 플래그십 엔진입니다. 실점유 VRAM은 Q4 기준 약 230GB에서 250GB를 초과합니다. 로컬 단말 구동 목적보다는, 하위 경량 모델들을 추가 파인튜닝(Fine-Tuning)하기 위한 교사 데이터 생성(Synthetic Data Generation) 및 증류(Distillation) 파이프라인의 최고 사령탑 모델로 유용합니다.
Gemma 2 매개변수별 프로필 상세 분석
- 2B 모바일 및 소형 임베디드 장치에 이식하기 위한 실험적 초경량 규격입니다. Q4 양자화 적용 시 약 1.8GB에서 2.2GB VRAM 수준으로 작동합니다. 체급에 비해 구글의 대화형 강화학습 튜닝이 훌륭하게 이식되어, 비정형 자연어 일상 대화나 안내 키오스크용 실시간 음성 응답 에이전트의 프론트헤드 엔진으로 대단히 자연스러운 문장력을 구사합니다. 코딩이나 고차원 수학 연산은 연산 표현 능력이 부족하여 쉽게 붕괴됩니다.
- 9B 가용 VRAM 8GB에서 12GB 사이의 보급형 단말 인프라에서 최상의 자연어 표현력을 뿜어내는 베스트셀러 모델입니다. Q4 양자화 상태에서 실점유 VRAM은 약 7.5GB에서 8.5GB입니다. 벤치마크 점수가 타사 8B 체급을 완전히 추월하며, 인간 편집자가 정제한 듯 수려하고 세련된 어휘를 선택하여 마케팅 문안 작성, 이메일 답장 초안 생성, 블로그 텍스트 보강 등 자연어 작문 워크플로우에 최상의 결과물을 선사합니다. 일부 구버전 Ollama 및 llama.cpp 구동 시 슬라이딩 윈도우 어텐션 캐시 할당 버그로 메모리 누수가 나타날 수 있으므로 항상 최신 런타임 버전 갱신이 수반되어야 합니다.
- 27B 단일 RTX 3090/4090(24GB) 및 Mac Studio M4 Max 64GB 환경에서 강력 추천하는 감성 추론 모델입니다. GGUF Q4_K_M 기준 실질 점유 VRAM은 약 18GB에서 20GB 수준입니다. 9B 모델에 비해 답변의 구조적 일관성과 정보 압축 요약 지능이 극적으로 상승하였으며, 기업의 1대1 맞춤형 고객 상담 챗봇 엔진이나 인공지능 심리 서포터 등 섬세한 언어 감수성과 높은 정보 신뢰도를 동시에 충족해야 하는 시스템에 안착하기에 최적입니다.
Phi-4 및 Phi-3 매개변수별 프로필 상세 분석
- 3.8B (Phi-3 Mini) 일반 사무용 울트라북 등 내장 그래픽만 탑재된 하드웨어 온보드 환경에서 초고속으로 실시간 텍스트를 흘려보내기 위한 전용 소형 모델입니다. Q4 기준 약 2.2GB에서 2.6GB VRAM만 할당받아 즉시 로드됩니다. 마이크로소프트가 고도로 정제된 논리 서적 및 학술 합성 데이터를 매핑하여 학습시킨 덕분에, 짧은 자연어 질의응답과 기초 문법 정정 작업에서 뛰어난 가성비를 발휘합니다. 단점은 4k 이상의 문맥이나 복잡한 RAG 질의를 쏟아부으면 급속하게 컨텍스트 드리프트 현상이 관찰되며 엉뚱한 영어 답변을 내뱉습니다.
- 14B (Phi-4) 가용 VRAM 12GB에서 16GB 단말에 강력 추천하는 최고 가성비의 논리 모델입니다. Q4 양자화 기준 실점유 VRAM은 약 9.5GB에서 10.5GB 선입니다. 최신 마이크로소프트의 수학/논리 추론 가속 학습 기법이 주입되어, 14B라는 아담한 체급임에도 수학 공식 풀이, 코딩 논리 오류 탐지, 구조적 연산에서 Llama 3.1 8B를 압도하고 Qwen 32B에 가까운 지능을 보여줍니다. RAG 파이프라인 상에서 외부 검색 덤프 데이터로부터 필요한 변수 값만 추출하여 JSON 포맷으로 스키마를 정렬 반환하는 백엔드용 데이터 추출 구조화 도구로 활용도가 극도로 높습니다.
- 42B (Phi-3.5 MoE / Active 6.6B) 총 매개변수 42B 중 활성화 매개변수 6.6B 크기로 작동하는 혼합 전문가 구조의 경량화 모델입니다. Q4 양자화 기준 실질 VRAM 점유량은 약 25GB에서 28GB입니다. 다단계 분할 태스크의 동시 수행 및 다국어 번역 성능이 크게 개선되었으며, 가벼운 액티브 파라미터 연산 덕분에 CPU가 탑재된 엣지 인프라에서도 실용적인 추론 속도를 실증합니다.
4.2. Mixture of Experts (MoE) 모델 엔진의 로컬 구동 원리
최근 로컬 AI 환경에서 가장 주목받는 흐름 중 하나는 바로 MoE(Mixture of Experts) 기술입니다. Mixtral 8x7B, Mixtral 8x22B, Qwen MoE 등에서 채택된 이 방식은 모델 내부의 가중치 네트워크를 여러 개의 전문가(Expert) 그룹으로 세분화하여 제어합니다.
사용자의 질문이 인입되면 라우터(Router) 네트워크가 실시간으로 입력 토큰의 성격을 분석한 뒤, 전체 매개변수 중 극히 일부인 지정 전문가 그룹(예: 8개의 전문가 중 토큰당 2개 전문가 활성화)에게만 연산 통행권을 배정합니다. 이로 인해 모델 전체의 물리적 파일 용량은 매우 크지만, 실제 토큰 하나를 생성하는 데 가용되는 액티브 연산량은 소형 모델 크기로 줄어들어 추론 연산 지연을 획기적으로 개선합니다.
4.3. MoE 아키텍처와 Apple Silicon 통합 메모리(UMA)의 기술적 시너지
MoE 아키텍처의 최대 한계는 VRAM 용량 요구 조건이 극도로 높다는 점입니다. 연산 시 활성화되는 매개변수는 일부일지라도, 전체 전문가 네트워크 가중치 파일(예: Mixtral 8x22B 기준 약 141B 크기) 전체가 비디오 메모리에 완전히 상주하고 있어야 실시간 라우팅이 성립하기 때문입니다. 비디오 메모리가 부족하여 시스템 RAM으로 파일이 분할 적재되면 극심한 PCIe 대역폭 병목으로 인해 추론 속도가 초당 1토큰 미만으로 붕괴됩니다.
이 지점에서 Mac Studio의 통합 메모리 아키텍처(UMA)가 진정한 파괴력을 보장합니다. 최대 128GB에서 192GB 이상의 풀 메모리를 공유하는 M3 Ultra 혹은 M4 Max 시스템은 백억 원대 초거대 가속기 장비를 도입하지 않고도 단일 미니 PC 장비로 141B MoE 모델 가중치 파일 전체를 초고속 전용 VRAM 영역에 적재할 수 있습니다. 메모리 공간 확보는 넉넉하되, 연산 자체는 액티브 전문가 크기(예: 39B)만 구동되므로 물리 연산 부하가 억제되어, 매우 부드럽고 매끄러운 생성 속도를 영위할 수 있는 것입니다. 즉, MoE 모델은 메모리 용량 우위를 지닌 Apple Silicon을 위해 설계되었다고 해도 무방할 정도로 완벽한 하드웨어 궁합을 보여줍니다.
4.4. VRAM 용량별 로컬 LLM 및 MoE 권장 사양 Matrix
하드웨어 환경의 한계 비디오 메모리(VRAM) 크기에 맞춰, 가장 안정적인 성능과 속도(t/s)를 담보할 수 있는 추천 오픈 LLM 엔진 및 양자화 규격 매핑 지표입니다.
| 가용 VRAM 크기 | 권장 오픈 LLM 엔진 | 추천 양자화 규격 | 용도 특징 |
|---|---|---|---|
| 8GB 미만 (RTX 3060 등) | Qwen 2.5 7B, Gemma 2 9B, DeepSeek-R1-Distill-Qwen 7B | Q4_K_M (GGUF) | 개인용 챗봇 |
| 16GB ~ 24GB (RTX 4090 등) | Llama 3.1 8B, Qwen 2.5 14B, DeepSeek-R1-Distill-Qwen 32B | Q8_0 / Q4_K_M (GGUF) | 개발용 비서 |
| 48GB ~ 64GB (M4 Max 64GB) | Llama 3.3 70B, Qwen 2.5 32B, Mixtral 8x7B (MoE) | Q4_K_M / Q8_0 (GGUF) | 팀단위 코딩 서버 |
| 96GB 이상 (M3 Ultra 128GB) | Llama 3.3 70B, Qwen 2.5 72B, Mixtral 8x22B (MoE) | Q8_0 (GGUF) | 엔터프라이즈 AI |
05. Ollama 백그라운드 자동 기동 및 외부 접속 허용 설정
Mac OS 환경에서 Ollama를 상시 구동 상태의 시스템 API 서버로 동작시키기 위해서는 launchd 데몬 스크립트를 활용해 시스템 부팅 시 백그라운드 서비스로 자동 실행되도록 유치하고, 기본으로 묶여 있는 로컬 루프백 주소(127.0.0.1)를 개방 주소(0.0.0.0)로 전환해주어야 합니다.
launchd 에이전트 설정 파일 배치
사용자 로그인 시점에 Ollama 데몬이 자동으로 기동하며 환경변수를 바인딩할 수 있도록 plist 파일을 `~/Library/LaunchAgents/`에 작성합니다.
다음 launchd plist 에이전트 설정 파일 전문을 작성하여 지정 폴더에 안착시킵니다.
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE plist PUBLIC "-//Apple//DTD PLIST 1.0//EN" "http://www.apple.com/DTDs/PropertyList-1.0.dtd">
<plist version="1.0">
<dict>
<key>Label</key>
<string>com.ollama.service</string>
<key>ProgramArguments</key>
<array>
<string>/usr/local/bin/ollama</string>
<string>serve</string>
</key>
<key>RunAtLoad</key>
<true/>
<key>KeepAlive</key>
<true/>
<key>EnvironmentVariables</key>
<dict>
<key>OLLAMA_HOST</key>
<string>0.0.0.0</string>
<key>OLLAMA_ORIGINS</key>
<string>*</string>
</dict>
<key>StandardOutPath</key>
<string>/tmp/ollama.stdout.log</string>
<key>StandardErrorPath</key>
<string>/tmp/ollama.stderr.log</string>
</dict>
</plist>시스템 데몬 서비스 로드 및 외부 접근 개방
파일의 실행 소유자 권한을 부여하고 launchctl 부트스트랩 명령어를 실행하여 외부 접속 주소(0.0.0.0)를 전격 개방합니다.
chmod 644 ~/Library/LaunchAgents/com.ollama.service.plist
launchctl bootstrap gui/$(id -u) ~/Library/LaunchAgents/com.ollama.service.plist06. Nginx 리버스 프록시 연동 및 basic_auth 보안 제어
동일 네트워크 안에서 포트를 개방하는 것을 넘어, 외부 인터넷망을 통해 로컬 서버에 접속하거나 보안 무방비 상태의 API 포트를 보호하기 위해서는 전면에 웹 서버인 Nginx를 배치하여 역방향 프록시(Reverse Proxy)를 결합하고 Basic Access Authentication 보안 계층을 강제해야 합니다.
Nginx 보안 프록시 구성 및 Basic Auth 강제
웹 포트 80을 수신처로 지정하고, 암호 해시 파일(htpasswd) 경로를 지명한 뒤 Nginx 설정 전처리 문법 검사를 마칩니다.
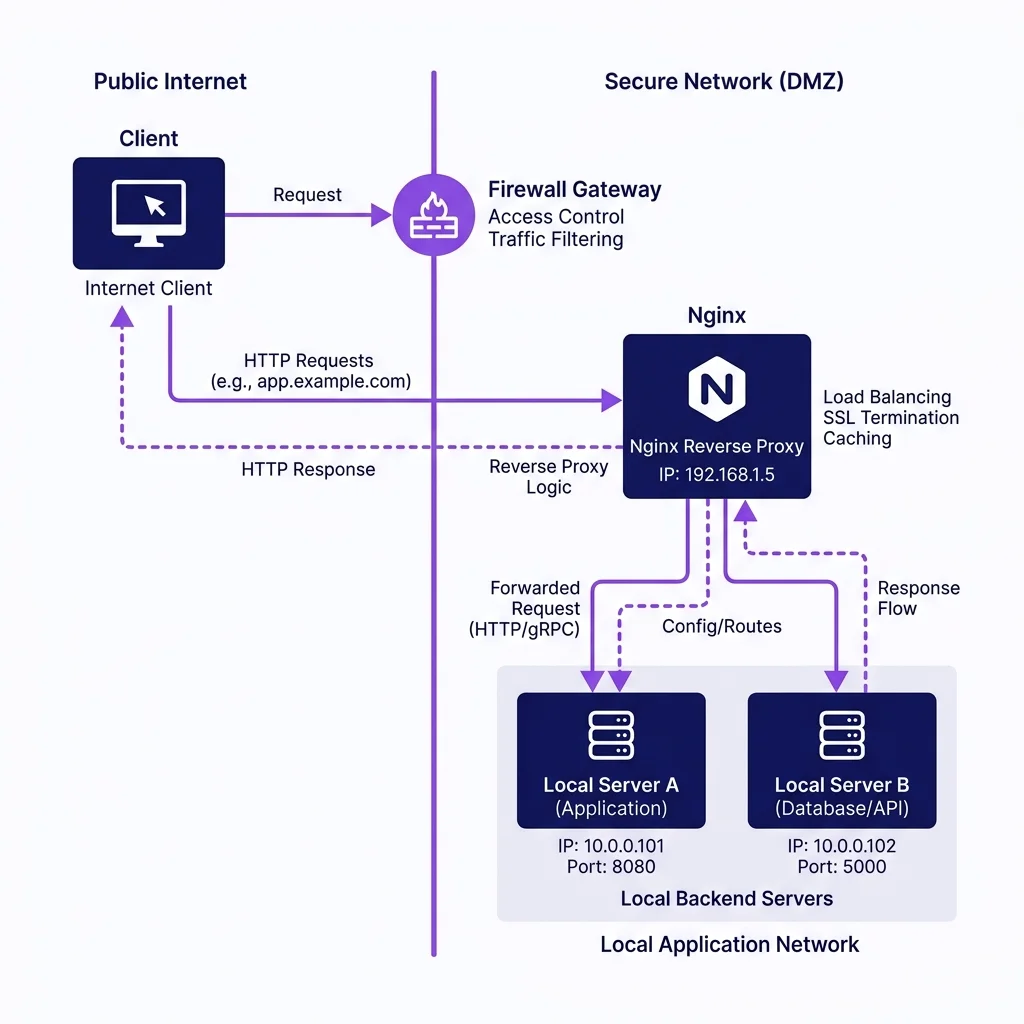
Nginx 설정 파일 내부의 프록시 및 인증 서버 템플릿입니다.
server {
listen 80;
server_name local-ai-server.lan;
# 보안을 위해 모든 Ollama API 요청에 대해 기본 Basic Auth 적용
auth_basic "Restricted Local AI API Access";
auth_basic_user_file /etc/nginx/.htpasswd;
location / {
proxy_pass http://127.0.0.1:11434;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
# LLM 스트리밍 응답을 위해 버퍼링 해제 필수
proxy_buffering off;
proxy_read_timeout 600s;
proxy_send_timeout 600s;
}
}sudo htpasswd -c /etc/nginx/.htpasswd tippickouser
sudo nginx -t
sudo systemctl restart nginx07. 실전 API 연동 코드 가이드
구축된 로컬 LLM API 서버를 활용해 외부 클라이언트 스크립트에서 호출을 날리고 비동기 스트리밍 응답을 입수하는 파이썬 코드 가이드라인입니다.
파이썬 연동 및 스트리밍 확인
OpenAI 라이브러리 및 Requests 모듈을 호출하여 프록시 인증을 경유하고 로컬 챗 completions API 스트림 연동을 완수합니다.
파이썬 OpenAI SDK 호환 호출 예제 코드 전문입니다.
import openai
# Nginx를 통해 인가된 basic_auth 계정을 URL 내부에 매핑하여 클라이언트 선언
client = openai.OpenAI(
base_url="http://tippickouser:my_secret_password@local-ai-server.lan/v1",
api_key="local-server-bypass-key" # 임의의 값 가능
)
try:
response = client.chat.completions.create(
model="llama3:8b",
messages=[
{"role": "system", "content": "당신은 로컬 인프라 전문가입니다. 간결하게 답변하세요."},
{"role": "user", "content": "Apple Silicon이 LLM에 유리한 이유가 무엇인가요?"}
],
stream=True
)
print("[실시간 스트리밍 답변 수신]")
for chunk in response:
content = chunk.choices[0].delta.content
if content:
print(content, end="", flush=True)
print("
[수신 완료]")
except Exception as e:
print(f"API 연결 또는 연산 실패: {e}")requests 라이브러리를 사용해 스트림을 직접 파싱하는 로우 레벨 코드입니다.
import requests
import json
api_url = "http://local-ai-server.lan/api/chat"
auth_credentials = ("tippickouser", "my_secret_password")
payload = {
"model": "llama3:8b",
"messages": [
{"role": "user", "content": "Unified Memory Architecture의 대역폭 한계 극복 기법은?"}
],
"stream": True
}
try:
response = requests.post(
api_url,
auth=auth_credentials,
json=payload,
stream=True
)
if response.status_code == 200:
print("[Ollama API Stream Start]")
for line in response.iter_lines():
if line:
decoded_line = line.decode("utf-8")
json_data = json.loads(decoded_line)
token = json_data.get("message", {}).get("content", "")
print(token, end="", flush=True)
print("
[Ollama API Stream End]")
else:
print(f"서버 에러 응답 코드: {response.status_code}")
except requests.exceptions.RequestException as e:
print(f"통신 연결 장애 발생: {e}")실무형 Q&A 스크립트: 트러블슈팅 가이드
서버 구동 및 프록시 설정 시 엔지니어들이 겪는 난제와 해결 수칙을 슬랙 스레드 스타일로 요약 정리합니다.
기본적으로 Ollama는 보안을 위해 127.0.0.1 로컬 환경에만 바인딩됩니다. plist 내의 EnvironmentVariables 딕셔너리에 OLLAMA_HOST=0.0.0.0 과 OLLAMA_ORIGINS=* 환경 변수 키가 올바르게 주입되었는지 체크하십시오. 또한 Mac OS 자체 방화벽 설정(시스템 환경설정 > 네트워크 > 방화벽)에서 인입 연결 차단 조치가 켜져 있는지 확인하여 포트 11434를 승인해주어야 합니다.
Nginx의 기본 버퍼링 정책 때문입니다. Nginx는 클라이언트로 데이터를 보내기 전에 내부 버퍼를 가득 채우려 하므로, 실시간 텍스트 생성 응답이 먹통이 된 것처럼 몰아서 쏟아지게 됩니다. 가상 서버 설정 내의 ‘location /’ 블록 하부에 반드시 ‘proxy_buffering off;’ 구문을 명문화하여 버퍼링 제어를 수동 해제해주어야 즉각적인 한 토큰 단위 실시간 스트리밍 출력이 성립합니다.
통합 메모리 용량을 초과하는 대형 모델을 적재하여 메인 시스템 RAM과 PCIe 가상 교환(Swap) 오버헤드가 걸렸을 때 발생하는 전형적인 증상입니다. 모델의 양자화 단계를 Q4_K_M 등 더 경량화된 모델로 조절하십시오. 또한 실행 인수를 통해 가용 메모리 점유 임계치를 70~80% 선으로 강제 바인딩하여 백그라운드 OS 가용 메모리 공간을 보장해야 충돌을 방지할 수 있습니다.
결론 및 인프라 결정 권고안
로컬 LLM API 서버 구축은 클라우드 종속성 탈피와 철저한 기밀성 확보의 첫걸음입니다. 특히 하드웨어 관점에서 Mac Studio M4 Max 64GB 사양은 동급 최강의 전력 대비 대역폭(546 GB/s) 효율을 보여주어 개인화된 개발망에 대화용 8B 모델(최대 100 t/s)을 원스톱 가동하는 데 최상의 조화를 자랑합니다. 만약 다중 대화 수용과 70B 이상의 거대 모델을 상시 가동해야 한다면 UltraFusion 대역폭(819 GB/s)을 지닌 M3 Ultra 128GB 장비를 도입함으로써 엔비디아 H100 가속기 부럽지 않은 가성비 최고의 전용 로컬 AI 지식 허브를 구축할 수 있습니다.
하드웨어와 적절한 구동 데몬, 그리고 Nginx 가상 프록시 결합으로 이어지는 본 아키텍처 수립 지침을 인프라 설계에 이식하여 안전하고 빠른 오프라인 LLM 지식베이스 인프라를 완성하시기 바랍니다.