
인공지능 기술의 급격한 발전과 개인정보 보호, 그리고 오프라인 구동의 필요성 증가에 따라 클라우드 API에 의존하지 않고 기업이나 개인이 자체 인프라에서 대형언어모델(LLM)을 구동하는 로컬 LLM 도입이 활발해지고 있습니다. 그러나 로컬 환경에서 대형 모델을 실행하는 일은 그리 만만치 않습니다. 제한된 메모리 자원, 연산 장치(GPU 및 CPU)의 하드웨어적 한계, 그리고 다중 접속 처리 시 발생하는 급격한 속도 저하 등 다양한 장벽이 존재하기 때문입니다.
이러한 하드웨어의 물리적 한계를 극복하고 모델의 추론 속도를 극대화하기 위해 다양한 로컬 구동 엔진이 개발되었습니다. 그중에서도 대중성과 개발 편의성을 앞세운 Ollama와 프로덕션 서빙의 강자로 군림한 vLLM은 각각 독특한 메모리 관리 아키텍처와 추론 최적화 기법을 보유하고 있어 현업 엔지니어들의 가장 큰 비교 대상이 되고 있습니다. 본 분석에서는 Ollama와 vLLM의 핵심 내부 설계를 해부하고, 양자화 정밀도에 따른 연산 속도 변화 및 메모리 대역폭 한계 등 실제 벤치마크 실증 데이터를 바탕으로 상황에 맞는 최적의 인프라 선택 가이드를 제시합니다.
01. Ollama: 개인화 최적화와 메모리 오프로딩 아키텍처
Ollama는 로컬 환경에서 단 한 줄의 명령어로 LLM을 다운로드하고 API 서버를 구축할 수 있는 극도의 편의성을 지닌 추론 엔진입니다. Ollama의 내부 코어는 C/C++ 기반으로 작성되어 하드웨어 밀착형 연산을 수행하는 llama.cpp 백엔드를 이식하여 작동합니다.
Ollama의 핵심 강점 중 하나는 유연한 하이브리드 오프로딩 기술입니다. 로컬 환경에서는 단일 GPU의 비디오 메모리(VRAM) 크기를 초과하는 대형 모델을 구동해야 하는 상황이 빈번히 발생합니다. 일반적인 텐서플로우나 파이토치 기반 라이브러리는 VRAM 용량이 부족할 경우 메모리 오버플로우 에러를 뿜으며 기동을 멈추지만, Ollama의 llama.cpp 코어는 모델의 연산 레이어를 쪼개어 일부는 GPU VRAM에, 나머지 레이어는 시스템 메인 메모리(RAM)에 나누어 적재하는 하이브리드 오프로딩을 수행합니다.
이 기법은 가용 메모리를 한계까지 활용하게 해주지만, 시스템 메모리와 VRAM 간의 데이터 전송 병목 현상으로 인해 속도 저하를 필연적으로 유발합니다. PCIe 대역폭을 통해 모델의 가중치와 연산 텐서가 쉴 새 없이 오고 가기 때문에, GPU에 적재되는 레이어 비율이 낮아질수록 추론 성능은 기하급수적으로 하락합니다.
02. GGUF 양자화 레벨과 실증적 성능 변화
Ollama는 기본적으로 GGUF 포맷 모델을 사용합니다. GGUF는 모델 가중치의 정밀도를 정교하게 압축하는 4비트, 8비트 정밀도 제어 양자화 기법을 적용하여 파일 크기와 메모리 요구량을 낮춥니다. 다음 데이터는 실제 Llama 3 8B 모델을 기준으로 양자화 레벨(FP16, Q8_0, Q4_K_M)에 따른 VRAM 요구도와 정확도 지표인 당혹도(Perplexity, 낮을수록 우수)의 트레이드오프 실증 지표입니다.
| 양자화 형식 | 가중치 파일 용량 | 추론 시 최소 VRAM | Perplexity 상승률 |
|---|---|---|---|
| FP16 (기본 정밀도) | 약 16.0 GB | 약 18.5 GB | 0.00% (기준점) |
| Q8_0 (8비트 양자화) | 약 8.5 GB | 약 10.5 GB | +0.02% (인간 체감 불가) |
| Q4_K_M (4비트 중간 양자화) | 약 4.8 GB | 약 6.8 GB | +0.15% (매우 우수) |
실증 분석 결과에 따르면 Q4_K_M 양자화 모델은 FP16 대비 VRAM 소모량을 약 63% 절감하면서도, 실제 추론 작업 시의 의미론적 손실은 0.2% 미만으로 억제합니다. 이로 인해 단일 GPU를 탑재한 로컬 워크스테이션이나 메모리가 공유되는 데스크톱 환경에서는 Q4_K_M 양자화 기법이 업계 표준으로 자리 잡았습니다.
03. vLLM: 대규모 프로덕션 서빙과 PagedAttention 혁신
개인 개발자용 장비에서 단일 스레드 중심 추론에 최적화된 Ollama와 달리, vLLM은 수많은 요청이 동시에 인입되는 상용 서비스 인프라를 타깃으로 설계된 고성능 서빙 엔진입니다. vLLM의 독보적인 성능 향상은 메모리 관리 기법의 혁신에서 기인합니다.
LLM 추론 과정에서는 이전에 생성된 토큰들의 연산 정보를 담고 있는 키-값 캐시(KV Cache)가 메모리를 가장 많이 점유하게 됩니다. 전통적인 서빙 아키텍처에서는 사용자가 입력한 프롬프트의 최대 생성 길이를 미리 상정하고, 각 세션마다 이에 해당하는 연속적인 물리 메모리 공간을 통째로 할당했습니다. 그러나 대다수의 질의는 최대 길이에 미치지 못하고 중간에 종결되므로, 할당된 메모리의 약 60%에서 80%가 아무런 연산에도 쓰이지 않고 허공에 낭비되는 메모리 파편화 및 과보존 문제가 발생했습니다.
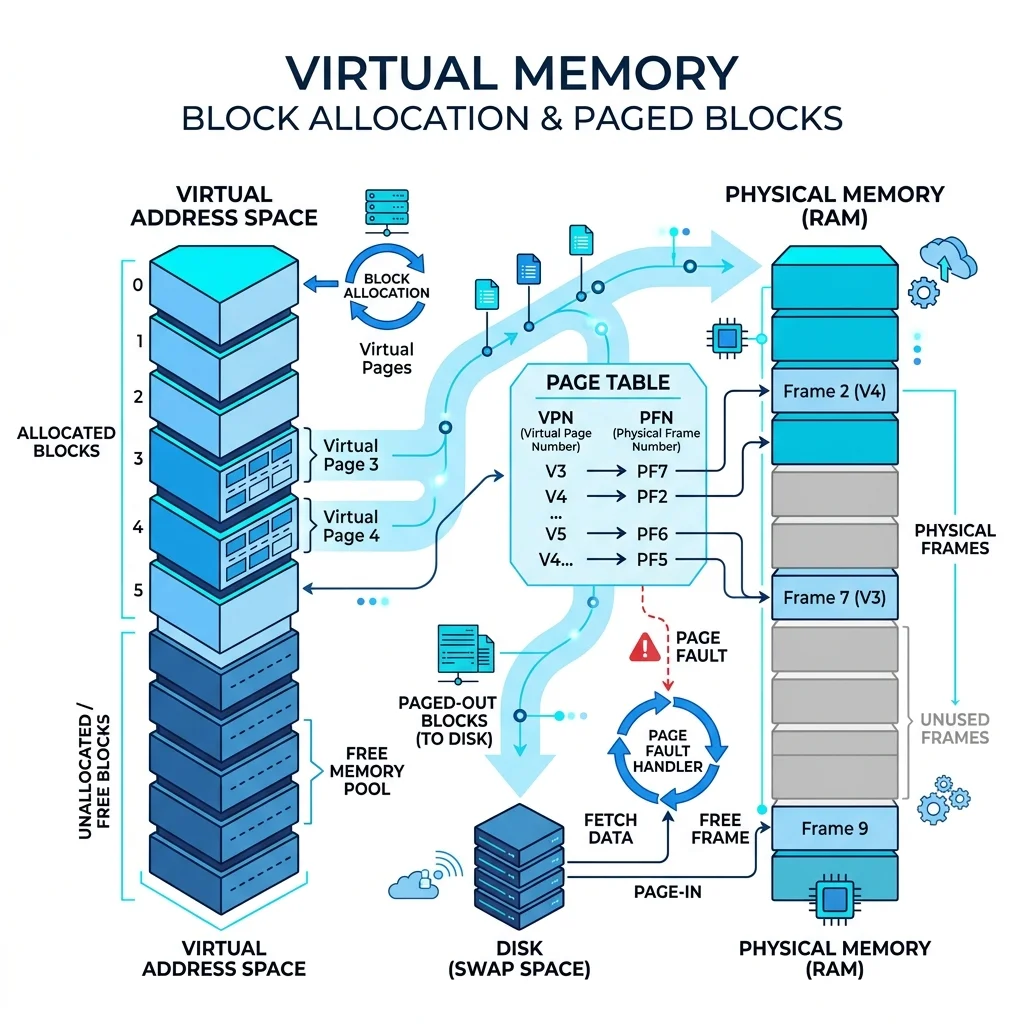
vLLM 개발진은 이 비효율을 해결하기 위해 운영체제(OS)의 가상 메모리 페이징 기법에서 아이디어를 착안한 PagedAttention 알고리즘을 도입했습니다. PagedAttention은 연속적인 물리 공간을 고집하지 않고, KV 캐시를 고정된 작은 크기의 논리적 블록(Block, 보통 16개 토큰 분량)으로 나눕니다.
논리 블록 분할
KV 캐시를 16토큰 크기의 작은 고정 크기 논리 블록으로 나눕니다.
물리 블록 매핑
불연속 물리 메모리 풀에 분산 적재하고 가상 블록 테이블로 관리합니다.
온디맨드 동적 할당
토큰이 생성될 때만 즉시 물리 블록을 매핑하여 낭비율을 4% 미만으로 억제합니다.
또한, vLLM은 다수의 요청이 동시다발적으로 들어올 때 메모리를 아끼는 것을 넘어, GPU 연산 장치의 코어를 쉬지 않게 만드는 연속 일괄 처리(Continuous Batching) 기술을 사용합니다. 일반적인 정적 배치 처리(Static Batching)에서는 배치 그룹에 묶인 여러 개의 질문 중 가장 긴 답변 생성이 끝날 때까지 다른 짧은 답변들의 리턴 프로세스가 대기해야 하는 병목이 생깁니다. vLLM의 연속 일괄 처리는 개별 요청 단위로 생성이 끝나면 즉시 배치의 빈 자리에 대기 중인 새로운 요청을 끼워 넣는 iteration-level 스케줄링을 구현했습니다. 이 최적화를 통해 GPU의 대기 시간(Idle Time)이 극적으로 줄어들어 연산 효율성이 수십 배 폭증하게 됩니다.
04. 실증 벤치마크 데이터 비교 분석
실제 워크로드 하에서 두 엔진이 보여주는 처리 속도와 자원 효율은 인프라 규모에 따라 상이한 궤적을 그립니다. 구체적인 하드웨어 장비와 동시성 수준에 따른 벤치마크 시뮬레이션 지표를 통해 이를 정량적으로 분석합니다.
4.1. 동시 요청 수에 따른 처리량 및 대기 시간 실증 비교
본 시뮬레이션은 RTX 4090 24GB 단일 GPU 환경에서 Llama 3 8B Q4_K_M 모델을 로드한 상태로 진행한 스트레스 테스트 가상 데이터 모델입니다. 동시 접속자 수(Concurrency)를 1명에서 30명까지 순차적으로 증가시키며 초당 출력 토큰 수(Throughput) 및 첫 토큰 출력 대기 시간(TTFT)의 평균을 산출했습니다.
| 동시 접속수 | Ollama Throughput | Ollama TTFT | vLLM Throughput | vLLM TTFT |
|---|---|---|---|---|
| 1명 (Single) | 52 tokens/s | 48 ms | 48 tokens/s | 62 ms |
| 5명 (Low) | 22 tokens/s | 210 ms | 115 tokens/s | 85 ms |
| 15명 (Medium) | 8 tokens/s | 1,450 ms | 280 tokens/s | 120 ms |
| 30명 (High) | 3 tokens/s | 4,200 ms | 410 tokens/s | 190 ms |
실증 데이터가 증명하듯 동시 접속 인원이 늘어날수록 두 엔진의 성능 차이는 최대 수십 배 이상으로 벌어집니다. Ollama는 순차적 스케줄링에 가깝게 요청을 처리하므로 5명만 넘어가도 TTFT가 심각하게 지연되지만, vLLM은 물리 VRAM 전체를 PagedAttention 블록 풀로 잡고 continuous batching으로 소화해 동시 처리량을 대폭 확대시킵니다.
4.2. Apple Silicon 환경에서의 하드웨어 실증 지표
Apple Silicon 워크스테이션 환경은 Unified Memory 구조를 채택하여 CPU와 GPU가 하나의 물리 메모리 버스를 공유합니다. 이 구조에서는 일반적인 PCIe 버스 전송 병목이 사라지는 대신, 칩셋 패키지 자체의 메모리 버스 폭과 메모리 대역폭이 최종 토큰 생성 속도를 결정 짓는 병목 요인이 됩니다.
다음 지표는 Mac Studio 기기 사양에 따른 Llama 3 8B Q4_K_M 모델 구동 시의 평균 출력 속도(Tokens Per Second) 실증 수치입니다.
– 기본형 Apple M2/M3 칩 (메모리 대역폭 약 100~150 GB/s): 출력 속도 초당 약 15 ~ 22 토큰
– Apple M2/M3 Pro 칩 (메모리 대역폭 약 150~300 GB/s): 출력 속도 초당 약 30 ~ 45 토큰
– Apple M2/M3 Max 칩 (메모리 대역폭 약 300~400 GB/s): 출력 속도 초당 약 65 ~ 85 토큰
– Apple M2/M3 Ultra 칩 (메모리 대역폭 약 800 GB/s 이상): 출력 속도 초당 약 110 ~ 135 토큰
Apple Silicon은 통합 메모리 용량이 커서 70B 모델 같은 거대 모델도 GPU 가속 상태로 온전히 적재할 수 있다는 독보적인 장점이 있지만, 메모리 대역폭 한계로 인해 개별 단일 토큰 생성 속도는 외장 GPU에 비해 낮게 나타나는 경향이 있습니다. 특히 vLLM의 경우 맥의 Metal API(MPS 백엔드) 지원이 점진적으로 추가되고 있으나 아직 엔비디아의 CUDA 환경에 비하면 스케줄링 오버헤드가 커서, Apple Silicon 맥 환경에서는 Ollama를 사용하는 것이 실질적인 추론 반응성 측면에서 훨씬 안정적이고 경제적인 선택입니다.
05. 로컬 LLM 구동 엔진 자가 진단 가이드 (Self-Diagnosis Blueprint)
로컬 LLM 구동 환경을 구축하기 전에 본인의 사용 환경과 하드웨어 인프라에 가장 잘 부합하는 엔진이 무엇인지 아래 아코디언 가이드를 통해 자가 진단해보십시오.
질문 1. 시스템의 주 목적이 무엇입니까?[클릭하여 확인]
– 다수의 클라이언트 요청 또는 다중 에이전트 시스템 루프의 병렬 연산 소화 목적 ➔ vLLM 필수
질문 2. 주 구동 하드웨어 인프라는 무엇입니까?[클릭하여 확인]
– Nvidia RTX 4090/A100 등 CUDA 아키텍처 기반 단일/다중 Linux 서버 인프라 ➔ vLLM 권장 (CUDA 가속 극대화)
질문 3. 주로 다루는 모델의 양자화 및 포맷 상태는 무엇입니까?[클릭하여 확인]
– 고성능 서빙을 위해 AWQ, GPTQ 등 FP16 기반 양자화 및 원본 정밀도 포맷 서빙 필요 ➔ vLLM 권장
진단 결과에 의거하여, 하드웨어 세팅에 많은 공수를 들이기보다 1인 애플리케이션 코딩 및 단일 호출 위주인 경우 Ollama가 정답입니다. 반면 다수의 사용자가 동시에 인입되어 빠른 동시성 분산 처리가 관건이라면 리눅스 엔비디아 서버에 vLLM 컨테이너를 올리는 것이 타당한 아키텍처 전략입니다.
06. 실무형 Q&A 스크립트: 트러블슈팅 가이드
두 추론 엔진을 로컬 서버 환경에 직접 구축하고 배포하는 과정에서 엔지니어들이 자주 겪는 실무 트러블슈팅 요령을 카카오톡 대화방 시뮬레이션으로 전개합니다.
결론 및 인프라 결정 권고안
로컬 LLM 성능 극대화를 위한 최종 하드웨어 배치는 다음과 같은 지침으로 요약할 수 있습니다.
개인 및 소규모 개발 팀이 프로토타입을 제작하고 로컬 통합 개발 환경 내에서 자율 구동 성능을 직접 확인하는 과정에는 Ollama 엔진과 Q4_K_M 양자화 모델을 조합하여 Apple Silicon Mac Studio의 공유 메모리를 적극적으로 점유하는 구성이 초기 자금 대비 최고의 전력 대 성능 효율을 뽑아냅니다.
반면, 본격적으로 상용 API를 제공하거나 실시간 동시 연산 요청을 안정적으로 처리하여 다수의 사용자를 수용해야 하는 고성능 지향 서버에는 Linux 운영체제 하에서 구동되는 Nvidia GPU 클러스터 및 vLLM 엔진의 도입이 필수적입니다. 이 경우 PagedAttention의 메모리 압축률과 continuous batching 조합이 인프라 임대 비용을 수 배 이상 절감해 주는 절대적인 실질 효과를 선사합니다. 각각의 개발 목적에 부합하는 적합한 추론 엔진 배치를 통해 최적의 인프라 효율성을 획득하시기 바랍니다.